European roboticists today released a powerful open-source artificial intelligence model that acts as a brain for industrial robots—helping them grasp and manipulate things with new dexterity.
The new model, SPEAR-1, was developed by researchers at the Institute for Computer Science, Artificial Intelligence and Technology (INSAIT) in Bulgaria. It may help other researchers and startups build and experiment with smarter hardware for factories and warehouses.
Just as open source language models have made it possible for researchers and companies to experiment with generative AI, Martin Vechev, a computer scientist at INSIAT and ETH Zurich, says SPEAR-1 should help roboticists to experiment and iterate rapidly. “Open-weight models are crucial for advancing embodied AI,” Vechev told WIRED ahead of the release.
SPEAR-1 differs from existing robot foundation models in that it incorporates 3D data into its training mix. This gives the model an enhanced understanding of the physical world, making it easier to understand how objects move through physical space.
Robot foundation models are generally built on top of vision language models (VLMs) which have a broad but limited grasp of the physical world because training tends to come from labeled 2D images. “Our approach tackles the mismatch between the 3D space the robot operates in and the knowledge of the VLM that forms the core of the robotic foundation model,” Vechev says.
SPEAR-1 is roughly as capable as commercial foundation models designed to operate robots, when measured on RoboArena, a benchmark that tests a model’s ability to get a robot to do things like squeeze a ketchup bottle, close a drawer, and staple pieces of paper together.
SPEAR-1 suggests that the quest to build more intelligent robots may involve both closed models like those from OpenAI, Google, and Anthropic, as well as open source variants like Llama, DeepSeek, and Qwen.
Robot intelligence is still in its infancy, though. It is possible to train an AI model to operate a robot arm so that it can reliably pick certain objects from a table. In practice, however, the model will need to be retrained from scratch if a different kind of robot arm is used or if the object or the environment are altered.
A new studyfrom MIT suggests the biggest and most computationally intensive AI models may soon offer diminishing returns compared to smaller models. By mapping scaling laws against continued improvements in model efficiency, the researchers found that it could become harder to wring leaps in performance from giant models whereas efficiency gains could make models running on more modest hardware increasingly capable over the next decade.
“In the next five to 10 years, things are very likely to start narrowing,” says Neil Thompson, a computer scientist and professor at MIT involved in the study.
Leaps in efficiency, like those seen with DeepSeek’s remarkably low-cost model in January, have already served as a reality check for the AI industry, which is accustomed to burning massive amounts of compute.
As things stand, a frontier model from a company like OpenAI is currently much better than a model trained with a fraction of the compute from an academic lab. While the MIT team’s prediction might not hold if, for example, new training methods like reinforcement learning produce surprising new results, they suggest that big AI firms will have less of an edge in the future.
Hans Gundlach, a research scientist at MIT who led the analysis, became interested in the issue due to the unwieldy nature of running cutting edge models. Together with Thompson and Jayson Lynch, another research scientist at MIT, he mapped out the future performance of frontier models compared to those built with more modest computational means. Gundlach says the predicted trend is especially pronounced for the reasoning models that are now in vogue, which rely more on extra computation during inference.
Thompson says the results show the value of honing an algorithm as well as scaling up compute. “If you are spending a lot of money training these models, then you should absolutely be spending some of it trying to develop more efficient algorithms, because that can matter hugely,” he adds.
The study is particularly interesting given today’s AI infrastructure boom (or should we say “bubble”?)—which shows little sign of slowing down.
OpenAI and other US tech firms have signed hundred-billion-dollar deals to build AI infrastructure in the United States. “The world needs much more compute,” OpenAI’s president, Greg Brockman, proclaimed this week as he announced a partnership between OpenAI and Broadcom for custom AI chips.
A growing number of experts are questioning the soundness of these deals. Roughly 60 percent of the cost of building a data center goes toward GPUs, which tend to depreciate quickly. Partnerships between the major players also appear circular and opaque.
Ever since DeepSeek burst onto the scene in January, momentum has grown around open source Chinese artificial intelligence models. Some researchers are pushing for an even more open approach to building AI that allows model-making to be distributed across the globe.
Prime Intellect, a startup specializing in decentralized AI, is currently training a frontier large language model, called INTELLECT-3, using a new kind of distributed reinforcement learning for fine-tuning. The model will demonstrate a new way to build competitive open AI models using a range of hardware in different locations in a way that does not rely on big tech companies, says Vincent Weisser, the company’s CEO.
Weisser says that the AI world is currently divided between those who rely on closed US models and those who use open Chinese offerings. The technology Prime Intellect is developing democratizes AI by letting more people build and modify advanced AI for themselves.
Improving AI models is no longer a matter of just ramping up training data and compute. Today’s frontier models use reinforcement learning to improve after the pre-training process is complete. Want your model to excel at math, answer legal questions, or play Sudoku? Have it improve itself by practicing in an environment where you can measure success and failure.
“These reinforcement learning environments are now the bottleneck to really scaling capabilities,” Weisser tells me.
Prime Intellect has created a framework that lets anyone create a reinforcement learning environment customized for a particular task. The company is combining the best environments created by its own team and the community to tune INTELLECT-3.
I tried running an environment for solving Wordle puzzles, created by Prime Intellect researcher, Will Brown, watching as a small model solved Wordle puzzles (it was more methodical than me, to be honest). If I were an AI researcher trying to improve a model, I would spin up a bunch of GPUs and have the model practice over and over while a reinforcement learning algorithm modified its weights, thus turning the model into a Wordle master.
A four-legged robot that keeps crawling even after all four of its legs have been hacked off with a chainsaw is the stuff of nightmares for most people.
For Deepak Pathak, cofounder and CEO of the startup Skild AI, the dystopian feat of adaptation is an encouraging sign of a new, more general kind of robotic intelligence.
“This is something we call an omni-bodied brain,” Pathak tells me. His startup developed the generalist artificial intelligence algorithm to address a key challenge with advancing robotics: “Any robot, any task, one brain. It is absurdly general.”
Many researchers believe the AI models used to control robots could experience a profound leap forward, similar to the one that produced language models and chatbots, if enough training data can be gathered.
The AI-controlled robot is able to adapt to new, extreme circumstances, such as the loss of limbs.
Existing methods for training robotic AI models, such as having algorithms learn to control a particular system through teleoperation or in simulation, do not generate enough data, Pathak says.
Skild’s approach is to instead have a single algorithm learn to control a large number of different physical robots across a wide range of tasks. Over time, this produces a model which the company calls Skild Brain, with a more general ability to adapt to different physical forms—including ones it has never seen before. The researchers created a smaller version of the model, called LocoFormer, for an academic paper outlining its approach.
The model is also designed to adapt quickly to a new situation, such as missing leg or treacherous new terrain, figuring out how to apply what it has learned to its new predicament. Pathak compares the approach to the way large language models can take on particularly challenging problems by breaking it down and feeding its deliberations back into its own context window—an approach known as in-context learning.
Other companies, including the Toyota Research Institute and a rival startup called Physical Intelligence, are also racing to develop more generally capable robot AI models. Skild is unusual, however, in how it is building models that generalize across so many different kinds of hardware.
LocoFormer is trained with large-scale RL on a variety of procedurally generated robots with aggressive domain randomization.
Courtesy of Skild
In one experiment, the Skild team trained their algorithm to control a large number of walking robots of different shapes. When the algorithm was then run on real two- and four-legged robots—systems not included in the training data—it was able to control their movements and have them walk around.
At one point, the team found that a four-legged robot running the company’s omni-bodied brain will quickly adapt when it is placed on its hind legs. Because it senses the ground beneath its hind legs, the algorithm operates the robot dog as if it were a humanoid, having it stroll around on its hind legs.
LocoFormer learns continuously through online experience. The policy can learn from falls in early trials to improve control strategies in later ones.
Courtesy of Skild
The generalist algorithm could also adapt extreme changes to a robot’s shape—when, for example, its legs were tied together, cut off, or modified to become longer. The team also tried deactivating two of the motors on a quadruped robot with wheels as well as legs. The robot was able to adapt by balancing on two wheels like an unsteady bicycle.
When facing large disturbances—such as morphological changes, motor failures, or weight changes—LocoFormer can rebuild such representations to achieve online adaptation.
Courtesy of Skild
Skild is testing the same approach for robot manipulation. It trained Skild Brain on a range of simulated robot arms and found that the resulting model could control unfamiliar hardware and adapt to sudden changes in its environment like a reduction in lighting. The startup is already working with some companies that use robot arms, Pathak says. In 2024 the company raised $300 million in a round that valued the company at $1.5 billion.
Pathak says the results might seem creepy to some, but to him they show the sparks of a kind of physical superintelligence for robots. “It is so exciting to me personally, dude,” he says.
What do you think of Skild’s multitalented robot brain? Send an email to ailab@wired.com to let me know.
Demos of AI agents can seem stunning, but getting the technology to perform reliably and without annoying (or costly) errors in real life can be a challenge. Current models can answer questions and converse with almost humanlike skill, and are the backbone of chatbots such as OpenAI’s ChatGPT and Google’s Gemini. They can also perform tasks on computers when given a simple command by accessing the computer screen as well as input devices like a keyboard and trackpad, or through low-level software interfaces.
Anthropic says that Claude outperforms other AI agents on several key benchmarks including SWE-bench, which measures an agent’s software development skills, and OSWorld, which gauges an agent’s capacity to use a computer operating system. The claims have yet to be independently verified. Anthropic says Claude performs tasks in OSWorld correctly 14.9 percent of the time. This is well below humans, who generally score around 75 percent, but considerably higher than the current best agents—including OpenAI’s GPT-4—which succeed roughly 7.7 percent of the time.
Anthropic claims that several companies are already testing the agentic version of Claude. This includes Canva, which is using it to automate design and editing tasks, and Replit, which uses the model for coding chores. Other early users include The Browser Company, Asana, and Notion.
Ofir Press, a postdoctoral researcher at Princeton University who helped develop SWE-bench, says that agentic AI tends to lack the ability to plan far ahead and often struggles to recover from errors. “In order to show them to be useful we must obtain strong performance on tough and realistic benchmarks,” he says, such as reliably planning a wide range of trips for a user and booking all the necessary tickets.
Kaplan notes that Claude can already troubleshoot some errors surprisingly well. When faced with a terminal error when trying to start a web server, for instance, the model knew how to revise its command to fix it. It also worked out that it had to enable popups when it ran into a dead end browsing the web.
Many tech companies are now racing to develop AI agents as they chase market share and prominence. In fact, it might not be long before many users have agents at their fingertips. Microsoft, which has poured upwards of $13 billion into OpenAI, says it is testing agents that can use Windows computers. Amazon, which has invested heavily in Anthropic, is exploring how agents could recommend and eventually buy goods for its customers.
Sonya Huang, a partner at the venture firm Sequoia who focuses on AI companies, says for all the excitement around AI agents, most companies are really just rebranding AI-powered tools. Speaking to WIRED ahead of the Anthropic news, she says that the technology works best currently when applied in narrow domains such as coding-related work. “You need to choose problem spaces where if the model fails, that’s okay,” she says. “Those are the problem spaces where truly agent native companies will arise.”
A key challenge with agentic AI is that errors can be far more problematic than a garble chatbot reply. Anthropic has imposed certain constraints on what Claude can do—for example, limiting its ability to use a person’s credit card to buy stuff.
If errors can be avoided well enough, says Press of Princeton University, users might learn to see AI—and computers—in a completely new way. “I’m super excited about this new era,” he says.
Today, OpenAI released a new research paper apparently aimed at showing it is serious about tackling AI risk by making its models more explainable. In the paper, researchers from the company lay out a way to peer inside the AI model that powers ChatGPT. They devise a method of identifying how the model stores certain concepts—including those that might cause an AI system to misbehave.
Although the research makes OpenAI’s work on keeping AI in check more visible, it also highlights recent turmoil at the company. The new research was performed by the recently disbanded “superalignment” team at OpenAI that was dedicated to studying the technology’s long-term risks.
The former group’s coleads, Ilya Sutskever and Jan Leike—both of whom have left OpenAI—are named as coauthors. Sutskever, a cofounder of OpenAI and formerly chief scientist, was among the board members who voted to fire CEO Sam Altman last November, triggering a chaotic few days that culminated in Altman’s return as leader.
ChatGPT is powered by a family of so-called large language models called GPT, based on an approach to machine learning known as artificial neural networks. These mathematical networks have shown great power to learn useful tasks by analyzing example data, but their workings cannot be easily scrutinized as conventional computer programs can. The complex interplay between the layers of “neurons” within an artificial neural network makes reverse engineering why a system like ChatGPT came up with a particular response hugely challenging.
“Unlike with most human creations, we don’t really understand the inner workings of neural networks,” the researchers behind the work wrote in an accompanying blog post. Some prominent AI researchers believe that the most powerful AI models, including ChatGPT, could perhaps be used to design chemical or biological weapons and coordinate cyberattacks. A longer-term concern is that AI models may choose to hide information or act in harmful ways in order to achieve their goals.
OpenAI’s new paper outlines a technique that lessens the mystery a little, by identifying patterns that represent specific concepts inside a machine learning system with help from an additional machine learning model. The key innovation is in refining the network used to peer inside the system of interest by identifying concepts, to make it more efficient.
OpenAI proved out the approach by identifying patterns that represent concepts inside GPT-4, one of its largest AI models. The company released code related to the interpretability work, as well as a visualization tool that can be used to see how words in different sentences activate concepts, including profanity and erotic content, in GPT-4 and another model. Knowing how a model represents certain concepts could be a step toward being able to dial down those associated with unwanted behavior, to keep an AI system on the rails. It could also make it possible to tune an AI system to favor certain topics or ideas.
Google’s AI Overviews feature draws on Gemini, a large language model like the one behind OpenAI’s ChatGPT, to generate written answers to some search queries by summarizing information found online. The current AI boom is built around LLMs’ impressive fluency with text, but the software can also use that facility to put a convincing gloss on untruths or errors. Using the technology to summarize online information promises can make search results easier to digest, but it is hazardous when online sources are contractionary or when people may use the information to make important decisions.
“You can get a quick snappy prototype now fairly quickly with an LLM, but to actually make it so that it doesn’t tell you to eat rocks takes a lot of work,” says Richard Socher, who made key contributions to AI for language as a researcher and, in late 2021, launched an AI-centric search engine called You.com.
Socher says wrangling LLMs takes considerable effort because the underlying technology has no real understanding of the world and because the web is riddled with untrustworthy information. “In some cases it is better to actually not just give you an answer, or to show you multiple different viewpoints,” he says.
Google’s head of search Liz Reid said in the company’s blog post late Thursday that it did extensive testing ahead of launching AI Overviews. But she added that errors like the rock eating and glue pizza examples—in which Google’s algorithms pulled information from a satirical article and jocular Reddit comment, respectively—had prompted additional changes. They include better detection of “nonsensical queries,” Google says, and making the system rely less heavily on user-generated content.
You.com routinely avoids the kinds of errors displayed by Google’s AI Overviews, Socher says, because his company developed about a dozen tricks to keep LLMs from misbehaving when used for search.
“We are more accurate because we put a lot of resources into being more accurate,” Socher says. Among other things, You.com uses a custom-built web index designed to help LLMs steer clear of incorrect information. It also selects from multiple different LLMs to answer specific queries, and it uses a citation mechanism that can explain when sources are contradictory. Still, getting AI search right is tricky. WIRED found on Friday that You.com failed to correctly answer a query that has been known to trip up other AI systems, stating that “based on the information available, there are no African nations whose names start with the letter ‘K.’” In previous tests, it had aced the query.
Google’s generative AI upgrade to its most widely used and lucrative product is part of a tech-industry-wide reboot inspired by OpenAI’s release of the chatbot ChatGPT in November 2022. A couple of months after ChatGPT debuted, Microsoft, a key partner of OpenAI, used its technology to upgrade its also-ran search engine Bing. The upgraded Bing was beset by AI-generated errors and odd behavior, but the company’s CEO, Satya Nadella, said that the move was designed to challenge Google, saying “I want people to know we made them dance.”
Some experts feel that Google rushed its AI upgrade. “I’m surprised they launched it as it is for as many queries—medical, financial queries—I thought they’d be more careful,” says Barry Schwartz, news editor at Search Engine Land, a publication that tracks the search industry. The company should have better anticipated that some people would intentionally try to trip up AI Overviews, he adds. “Google has to be smart about that,” Schwartz says, especially when they’re showing the results as default on their most valuable product.
Lily Ray, a search engine optimization consultant, was for a year a beta tester of the prototype that preceded AI Overviews, which Google called Search Generative Experience. She says she was unsurprised to see the errors that appeared last week given how the previous version tended to go awry. “I think it’s virtually impossible for it to always get everything right,” Ray says. “That’s the nature of AI.”
Folks, when dogs talk, we’re talking Biblical disruption. Do you think that future models will do worse on the law exams?
If nothing else, this week proves that the rate of AI progress isn’t slowing at all. Just ask the people building these models. “A lot of things have happened—internet, mobile,” says Demis Hassabis, cofounder of DeepMind and now Google’s AI czar, in a post-keynote chat at I/O. “AI is going maybe three or four times faster than those other revolutions. We’re in a period of 25 or 30 years of massive change.” When I asked Google search VP Liz Reid to name a big challenge, she didn’t say it was to keep the innovation going—instead, she cited the difficulty of absorbing the pace of change. “As the technology is early, the biggest challenge is about even what’s possible,” she says. “It’s understanding what the models are great at today, and what they are not great at but will be great at in three months or six months. The technology is changing so fast that you can get two researchers in the room who are working on the same project, and they’ll have totally different views when something is possible.”
There’s universal agreement in the tech world that AI is the biggest thing since the internet, and maybe bigger. And when non-techies see the products for themselves, they most often become believers too. (Including Joe Biden, after a March 2023 demo of ChatGPT.) That’s why Microsoft is well along on a total AI reinvention, why Mark Zuckerberg is now refocusing Meta to create artificial general intelligence, why Amazon and Apple are desperately trying to keep up, and why countless startups are focusing on AI. And because all of these companies are trying to get an edge, the competitive fervor is ramping up new innovations at a frantic page. Do you think it was a coincidence that OpenAI made its announcement a day before Google I/O?
Skeptics might try to claim that this is an industry-wide delusion, fueled by the prospect of massive profits. But the demos aren’t lying. We will eventually become acclimated to the AI marvels unveiled this week. The smartphone once seemed exotic; now it’s an appendage no less critical to our daily life than an arm or a leg. At a certain point AI’s feats, too, may not seem magical any more. But the AI revolution will change our lives, and change us, for better or worse. And we haven’t even seen GPT-5 yet.
Time Travel
Sure, I could be wrong about AI. But consider the last time I made such a call. In 1995, I joined Newsweek—the same organ where Clifford Stoll had just dismissed the internet as a hoax—and at the end of the year argued of this new digital medium, “This Changes Everything.” Some of my colleagues thought I’d bought into overblown hype. Actually, reality exceeded my hyperbole.
In 1995, the Internet ruled. You talk about a revolution? For once, the shoe fits. “In the long run it’s hard to exaggerate the importance of the Internet,” says Paul Moritz, a Microsoft VP. “It really is about opening communications to the masses.” And 1995 was the year that the masses started coming. “If you look at the numbers they’re quoting, with the Web doubling every 53 days, that’s biological growth, like a red tide or population of lemmings,” says Kevin Kelly, executive editor of WIRED. “I don’t know if we’ve ever seen technology exhibit that sort of growth.” In fact, there’s a raging controversy over exactly how many people regularly use the Net. A recent Nielsen survey pegged the number at an impressive 24 million North Americans. During the course of the year the discussion of the Internet ranged from sex to stock prices to software standards. But the most significant aspect of the Internet has nothing to do with money or technology, really. It’s us.
Altman confirmed Sutskever’s departure Tuesday in a post on the social platform X. In the months after Altman’s return to OpenAI, Sutskever had rarely made public appearances for the company. On Monday, OpenAI showed off a new version of ChatGPT capable of rapid-fire, emotionally tinged conversation. Sutskever was conspicuously absent from the event, streamed from the company’s San Francisco offices.
“OpenAI would not be what it is without him,” Altman wrote in his post on Sutskever’s departure. “I am happy that for so long I got to be close to such [a] genuinely remarkable genius, and someone so focused on getting to the best future for humanity.”
Altman’s post announced that Jakub Pachocki, OpenAI’s research director, would be the company’s new chief scientist. Pachocki has been with OpenAI since 2017.
In his own post on X, Sutskever acknowledged his departure and hinted at future plans. “After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and beneficial” under its current leadership team, he wrote. “I am excited for what comes next—a project that is very personally meaningful to me about which I will share details in due time.”
Sutskever has not spoken publicly in detail about his role in the ejection of Altman last year, but after the CEO was restored he expressed regrets. “I deeply regret my participation in the board’s actions. I never intended to harm OpenAI,” he posted on X in November. Sutskever has often spoken publicly of his belief that OpenAI was working towards developing so-called artificial general intelligence, or AGI, and of the need to do so safely.
Sutskever blazed a trail in machine learning from an early age, becoming a protégé of deep-learning pioneer Geoffrey Hinton at the University of Toronto. With Hinton and fellow grad student Alex Krizhevsky he cocreated an image-recognition system called AlexNet that stunned the world of AI with its accuracy and helped set off a flurry of investment in the then unfashionable technique of artificial neural networks.
Sustskever later worked on AI research at Google, where he helped establish the modern era of neural-network-based AI. In 2015 Altman invited him to dinner with Elon Musk and Greg Brockman to talk about the idea of starting a new AI lab to challenge corporate dominance of the technology. Sutskever, Musk, Brockman, and Altman became key founders of OpenAI, which was announced in December 2015. It later pivoted its model, creating a for-profit arm and taking huge investment from Microsoft and other backers. Musk left OpenAI in 2018 after disagreeing with the company’s strategy. The entrepreneur filed a lawsuit against the company in March this year claiming it had abandoned its founding mission of developing super-powerful AI to “benefit humanity,” and was instead enriching Microsoft.
Sutskever’s departure leaves just one of the four OpenAI board members who voted for Altman’s ouster with a role at the company. Adam D’Angelo, an early Facebook employee and CEO of Q&A site Quora, was the only existing member of the board to remain as a director when Altman returned as CEO.
There are plenty of apps you can turn to to generate pictures using artificial intelligence. Still, Midjourney remains one of the best and one of the most popular options, having launched in beta form in July 2022.
ChatGPT’s Creator Buddies Up to Congress | Future Tech
It’s not free to use: The price of admission starts at $10 a month or $96 a year, which gives you 3.3 hours of image generation time per month (images usually take around a minute to render). However, the quality of the end result may well tempt you into a subscription if you need a lot of AI art.
Assuming you’re ready to sign up (for a month at least), here’s how to get started with Midjourney—the commands you need to know, how to save and browse your images, and some of the capabilities of the generative AI tool.
Getting started
Midjourney works through Discord: You can join the Midjourney channel here, and you’ll need to sign up for a (free) Discord account if you don’t already have one. The next steps involve two bits of admin—agreeing to the Midjourney terms of service and signing up for one of the Midjourney subscription tiers. You’ll get a neat little table outlining the differences between each tier.
Midjourney does a decent job of explaining how everything works with all that out of the way. Unless you’re on one of the more expensive plans, you’ll be writing your prompts and getting your images through a channel that’s open to other users, so don’t be shy—it actually works well for getting inspiration from what other people are doing, and seeing what’s possible with the AI engine.
The on-boarding process is straightforward.Screenshot: Midjourney
To begin with, you’ll need to get involved in one of the #newbie channels, which are clearly linked on the left of the web interface. Click to jump to any one of them and see what’s happening—look at how different art styles are described to get different results, from “abstract expressive” to “hyper-realistic” and everything in between.
The other online location you need to know about is the official Midjourney website. While all of your image generation is done on Discord, this website is where you can find an archive of all the pictures you’ve made and browse through some of the other artwork that’s proving popular on the Midjourney network. From here you’re also able to read about updates to Midjourney.
Writing prompts
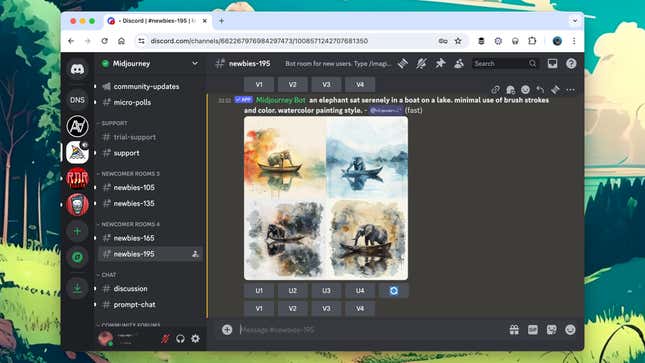
Head to a #newbie channel, type “/imagine” followed by a space, and you’re ready to start prompting. If you’ve never used an AI image generator before, describe what you want to see: You can be as creative as possible, putting any kind of person or object in any kind of setting and using any kind of artwork style.
As usual with generative AI tools, the more specific and precise you can be, the better. However, you can be vague if you want to (it’s just less likely you’ll get something close to what you were imagining). See a watercolor of an elephant in a boat, or a photo of an apple on a table, it’s up to you.
Type your prompts into one of the newbie channels.Screenshot: Midjourney
After a few moments of thinking, you’ll get four generated images based on your prompt—if you want Midjourney to try again, click the re-roll button (the blue-and-white circle of arrows). If you like one of the images more than the others, you can click one of the V1–V4 buttons to see four variations on it (the images are numbered from left to right and from top to bottom).
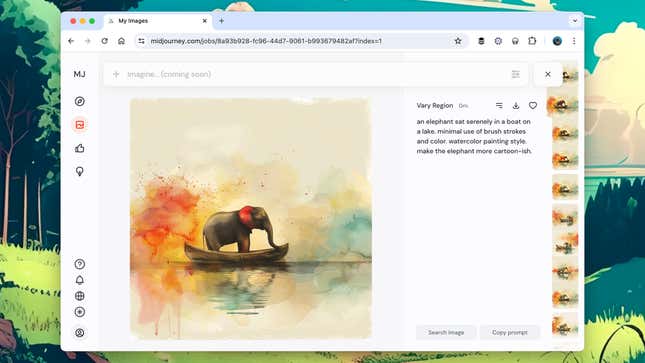
Click on any of the U1–U4 buttons to take a closer look. Here, you get access to some editing features: You’re able to create new variations on all or just part of the image, zoom out on the image (and have AI fill out the canvas), or extend the image in any direction using the four arrow buttons. Click on any image to see it in full-size mode, then right-click to save it somewhere else.
Going further
You can add a variety of parameters to your prompts, and there’s a full list here. They can be used to change an image’s aspect ratio, create images that will tile, or create more varied results, for example. So, if you need a wide rather than square picture, you might append “—aspect 16:9″ to the end of your prompt.
Also worth knowing about are the parameters “—cref” and “—sref”, both of which can be followed by a URL pointing at an image. Use the former (character reference) to show Midjourney a character you want to use in your pictures and the latter (style reference) to show Midjourney the style that you’d like your pictures to look like.
The Midjourney website collects all of your images.Screenshot: Midjourney
There are also a couple of other commands that you can use instead of “/imagine” on Discord. Use “/describe” to get Midjourney to return a text prompt based on an image you supply or “/blend” to have Midjourney combine up to five different images into something new. You can point to images on the web or upload them from your device.
Head to the Midjourney website to find all of your pictures and to download them whenever necessary—eventually, you’ll be able to generate images from here too, but the feature hasn’t been fully launched yet. You can use the filters on the right to sift through the artwork you’ve created, and it’s also possible to download multiple images at the same time or sort them into custom folders if required.
GlobalFoundries, a company that makes chips for others, including AMD and General Motors, previously announced a partnership with Lightmatter. Harris says his company is “working with the largest semiconductor companies in the world as well as the hyperscalers,” referring to the largest cloud companies like Microsoft, Amazon, and Google.
If Lightmatter or another company can reinvent the wiring of giant AI projects, a key bottleneck in the development of smarter algorithms might fall away. The use of more computation was fundamental to the advances that led to ChatGPT, and many AI researchers see the further scaling-up of hardware as being crucial to future advances in the field—and to hopes of ever reaching the vaguely-specified goal of artificial general intelligence, or AGI, meaning programs that can match or exceed biological intelligence in every way.
Linking a million chips together with light might allow for algorithms several generations beyond today’s cutting edge, says Lightmatter’s CEO Nick Harris. “Passage is going to enable AGI algorithms,” he confidently suggests.
The large data centers that are needed to train giant AI algorithms typically consist of racks filled with tens of thousands of computers running specialized silicon chips and a spaghetti of mostly electrical connections between them. Maintaining training runs for AI across so many systems—all connected by wires and switches—is a huge engineering undertaking. Converting between electronic and optical signals also places fundamental limits on chips’ abilities to run computations as one.
Lightmatter’s approach is designed to simplify the tricky traffic inside AI data centers. “Normally you have a bunch of GPUs, and then a layer of switches, and a layer of switches, and a layer of switches, and you have to traverse that tree” to communicate between two GPUs, Harris says. In a data center connected by Passage, Harris says, every GPU would have a high-speed connection to every other chip.
Lightmatter’s work on Passage is an example of how AI’s recent flourishing has inspired companies large and small to try to reinvent key hardware behind advances like OpenAI’s ChatGPT. Nvidia, the leading supplier of GPUs for AI projects, held its annual conference last month, where CEO Jensen Huang unveiled the company’s latest chip for training AI: a GPU called Blackwell. Nvidia will sell the GPU in a “superchip” consisting of two Blackwell GPUs and a conventional CPU processor, all connected using the company’s new high-speed communications technology called NVLink-C2C.
The chip industry is famous for finding ways to wring more computing power from chips without making them larger, but Nvidia chose to buck that trend. The Blackwell GPUs inside the company’s superchip are twice as powerful as their predecessors but are made by bolting two chips together, meaning they consume much more power. That trade-off, in addition to Nvidia’s efforts to glue its chips together with high-speed links, suggests that upgrades to other key components for AI supercomputers, like that proposed by Lightmatter, could become more important.
Aravind Srinivas credits Google CEO Sundar Pichai for giving him the freedom to eat eggs.
Srinivas remembers the moment seven years ago when an interview with Pichai popped up in his YouTube feed. His vegetarian upbringing in India had excluded eggs, as it had for many in the country, but now, in his early twenties, Srinivas wanted to start eating more protein. Here was Pichai, a hero to many aspiring entrepreneurs in India, casually describing his morning: waking up, reading newspapers, drinking tea—and eating an omelet.
Srinivas shared the video with his mother. OK, she said: You can eat eggs.
Pichai’s influence reaches far beyond Srinivas’ diet. He too is CEO of a search company, called Perplexity AI, one of the most hyped-up apps of the generative AI era. Srinivas is still taking cues from Pichai, the leader of the world’s largest search engine, but his admiration is more complicated.
“It’s kind of a rivalry now,” Srinivas says. “It’s awkward.”
Srinivas and Pichai both grew up in Chennai, India, in the south Indian state of Tamil Nadu—though the two were born 22 years apart. By the time Srinivas was working toward his PhD in computer science at UC Berkeley, Pichai had been crowned chief executive of Google.
For his first research internship, Srinivas worked at Google-owned DeepMind in London. Pichai also got a new job that year, becoming CEO of Alphabet as well as Google. Srinivas found the work at DeepMind invigorating, but he was dismayed to find that the flat he had rented sight unseen was a disaster—a “crappy home, with rats,” he says—so he sometimes slept in DeepMind’s offices.
He discovered in the office library a book about the development and evolution of Google, called In the Plex, penned by WIRED editor at large Steven Levy. Srinivas read it over and over, deepening his appreciation of Google and its innovations. “Larry and Sergey became my entrepreneurial heroes,” Srinivas says. (He offered to list In the Plex’s chapters and cite passages from memory; WIRED took his word for it.)
Shortly afterwards, in 2020, Srinivas ended up working at Google’s headquarters in Mountain View, California, as a research intern working on machine learning for computer vision. Slowly, Srinivas was making his way through the Google universe, and putting some of his AI research work to good use.
Then, in 2022, Srinivas and three cofounders—Denis Yarats, Johnny Ho, and Andy Konwinski—teamed up to try and develop a new approach to search using AI. They started out working on algorithms that could translate natural language into the database language SQL, but determined this was too narrow (or nerdy). Instead they pivoted to a product that combined a traditional search index with the relatively new power of large language models. They called it Perplexity.
Perplexity is sometimes described as an “answer” engine rather than a search engine, because of the way it uses AI text generation to summarize results. New searches create conversational “threads” on a particular topic. Type in a query, and Perplexity responds with follow up questions, asking you to refine your ask. It eschews direct links in favor of text-based or visual answers that don’t require you to click away to somewhere else to get information.
This week a startup called Cognition AI caused a bit of a stir by releasing a demo showing an artificial intelligence program called Devin performing work usually done by well-paid software engineers. Chatbots like ChatGPT and Gemini can generate code, but Devin went further, planning how to solve a problem, writing the code, and then testing and implementing it.
Devin’s creators brand it as an “AI software developer.” When asked to test how Meta’s open source language model Llama 2 performed when accessed via different companies hosting it, Devin generated a step-by-step plan for the project, generated code needed to access the APIs and run benchmarking tests, and created a website summarizing the results.
It’s always hard to judge staged demos, but Cognition has shown Devin handling a wide range of impressive tasks. It wowed investors and engineers on X, receiving plenty of endorsements, and even inspired a fewmemes—including some predicting Devin will soon be responsible for a wave of tech industry layoffs.
Devin is just the latest, most polished example of a trend I’ve been tracking for a while—the emergence of AI agents that instead of just providing answers or advice about a problem presented by a human can take action to solve it. A few months back I test drove Auto-GPT, an open source program that attempts to do useful chores by taking actions on a person’s computer and on the web. Recently I tested another program called vimGPT to see how the visual skills of new AI models can help these agents browse the web more efficiently.
I was impressed by my experiments with those agents. Yet for now, just like the language models that power them, they make quite a few errors. And when a piece of software is taking actions, not just generating text, one mistake can mean total failure—and potentially costly or dangerous consequences. Narrowing the range of tasks an agent can do to, say, a specific set of software engineering chores seems like a clever way to reduce the error rate, but there are still many potential ways to fail.
Not only startups are building AI agents. Earlier this week I wrote about an agent called SIMA, developed by Google DeepMind, which plays video games including the truly bonkers title Goat Simulator 3. SIMA learned from watching human players how to do more than 600 fairly complicated tasks such as chopping down a tree or shooting an asteroid. Most significantly, it can do many of these actions successfully even in an unfamiliar game. Google DeepMind calls it a “generalist.”
I suspect that Google has hopes that these agents will eventually go to work outside of video games, perhaps helping use the web on a user’s behalf or operate software for them. But video games make a good sandbox for developing and testing agents, by providing complex environments in which they can be tested and improved. “Making them more precise is something that we’re actively working on,” Tim Harley, a research scientist at Google DeepMind, told me. “We’ve got various ideas.”
You can expect a lot more news about AI agents in the coming months. Demis Hassabis, the CEO of Google DeepMind, recently told me that he plans to combine large language models with the work his company has previously done training AI programs to play video games to develop more capable and reliable agents. “This definitely is a huge area. We’re investing heavily in that direction, and I imagine others are as well.” Hassabis said. “It will be a step change in capabilities of these types of systems—when they start becoming more agent-like.”