
In 2011, Apple introduced Siri. This voice recognition system was designed as an ever-present digital assistant, that could help you with anything, anytime, anywhere. In 2014, Amazon introduced Alexa, which was designed to serve a similar purpose. Nearly a decade later, neither product has ever reached its potential. They are mostly niche tools that are used for very discrete purposes. Today’s New York Times explains how Siri, Alexa, as well as Google Assistant lost the A.I. race to tools like GPT. Now, we have another notch in the belt of OpenAI’s groundbreaking technology.
Yesterday, OpenAI released GPT-4. To demonstrate how powerful this tool is, the company allowed a number of experts to take the system for a spin. In the legal corner were Daniel Martin Katz, Mike Bommarito, Shang Gao, and Pablo Arredondo. In January 2023, Katz and Bommarito studied whether GPT-3.5 could pass the bar. At that time, the AI tech achieved an overall accuracy rate of about 50%.
In their paper, the authors concluded that GPT-4 may pass the bar “within the next 0-18 months.” The low-end of their estimate proved to be accurate.
Fast-forward to today. Beware the Ides of March. Katz, Bommarito, Gao, and Arredondo posted a new paper to SSRN, titled “GPT-4 Passes the Bar Exam.” Here is the abstract:
In this paper, we experimentally evaluate the zero-shot performance of a preliminary version of GPT-4 against prior generations of GPT on the entire Uniform Bar Examination (UBE), including not only the multiple-choice Multistate Bar Examination (MBE), but also the open-ended Multistate Essay Exam (MEE) and Multistate Performance Test (MPT) components. On the MBE, GPT-4 significantly outperforms both human test-takers and prior models, demonstrating a 26% increase over ChatGPT and beating humans in five of seven subject areas. On the MEE and MPT, which have not previously been evaluated by scholars, GPT-4 scores an average of 4.2/6.0 as compared to much lower scores for ChatGPT. Graded across the UBE components, in the manner in which a human tast-taker would be, GPT-4 scores approximately 297 points, significantly in excess of the passing threshold for all UBE jurisdictions. These findings document not just the rapid and remarkable advance of large language model performance generally, but also the potential for such models to support the delivery of legal services in society.
Figure 1 puts this revolution in stark contrast:

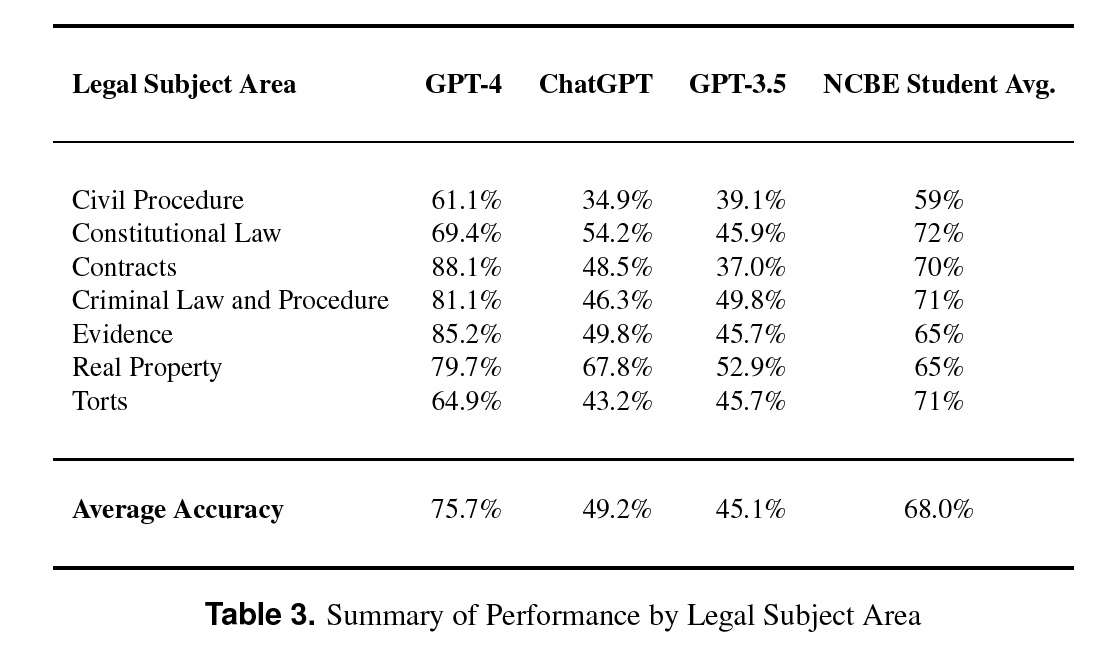
Two months ago, an earlier version of GPT was at the 50% mark. Now, GPT-4 exceeded the 75% mark, and exceeds the student average performance nationwide. GPT-4 would place in the 90th percentile of bar takers nationwide!
And GPT scored well across the board. Evidence is north of 85%, and GPT-4 scored nearly 70% in ConLaw!
We should all think very carefully how this tool will affect the future of legal services, and what we are teaching to our students.
Josh Blackman
Source link